Thoughtworks 技术雷达:AI 代码质量的新护栏
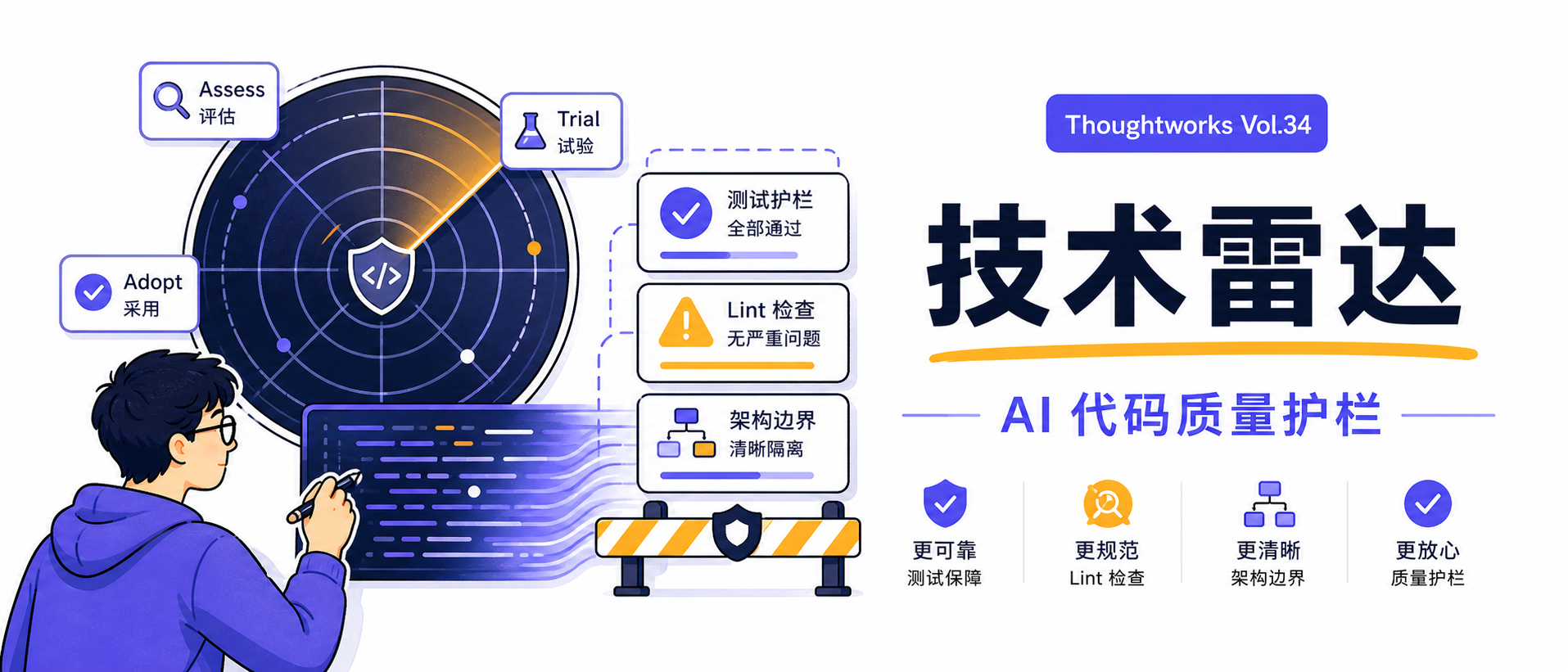
这是一份参考材料,整理 Thoughtworks Technology Radar Vol. 34 中和「AI 加速代码库腐败」有关的技术、工具和判断。
它不进入项目立项文档系列,也不代表本项目会采纳这些方案。这里只记录业界当前比较主流的处理方式。
一、背景
Thoughtworks 在 Vol. 34 里反复提到一个问题:AI 编码工具让软件复杂性增长得更快。代码变多了,理解代码的人反而可能更少。这就是他们说的 cognitive debt,也就是认知债。
Rachel Laycock 在发布稿里说,AI 的能力过去一年增长很快,但真正的拐点不是技术本身,而是 technique:人要主动建立实践和技术护栏,才能安全、有效地使用这些能力。
这句话很重要。它没有把 AI 代码质量问题归结为「模型还不够强」,而是把焦点放回工程方法。下面按「技术思路」和「具体工具」两层整理。
环位说明
Technology Radar 用环位表达成熟度和采纳建议:
| 环位 | 含义 |
|---|---|
| Adopt | 已经比较成熟,应认真考虑采用 |
| Trial | 可以在能承受风险的项目里试用 |
| Assess | 值得观察,不一定马上落地 |
| Hold / Caution | 谨慎使用,甚至主动回避 |
这里引用的是 Thoughtworks 自己的判断,来自他们在真实项目中的经验。Trial 通常意味着已经在生产环境里用过;Assess 更像是「方向值得看,但还没到大规模推荐」。
二、五个技术思路
1. 用 LLM 减少架构漂移
环位:Assess
AI Agent 会复刻既有代码模式。麻烦在于,它不只会学好模式,也会学坏模式。一个已经退化的代码库,会把退化模式继续喂给 Agent,最后形成「劣码生成劣码」的循环。
Thoughtworks 提到的做法是两层校验。
第一层是确定性工具。比如「controller 不能直接访问 repository」「领域包不能依赖框架」。这类规则可以用静态分析稳定判断,结果比较清楚。
第二层是 LLM 评估。它处理的是静态规则不好表达的东西,比如 API 命名是否符合项目风格、错误处理是否偏离惯例。这里 LLM 不应该被当成最终裁判,更适合作为发现问题和提出建议的助手。
这个方向可用于跨服务 API 质量准则,也可以用于给 Agent 划定 architectural zones。
Thoughtworks 也提醒了风险:第一次扫描通常会冒出大量违规项,需要先分拣优先级。Agent 修复要小而集中,修完还要有额外验证,防止它把系统改坏。
2. 给编码 Agent 装反馈传感器
环位:Trial
这是五个技术里成熟度最高的一个。
传统 CI 的问题是太晚。AI Agent 一晚上可能产生几十次「提交意图」,等提交后再跑 CI、再让人评审,反馈已经堆积起来了。
反馈传感器的思路很直接:把编译器、检查器、结构性测试和测试套件接进 Agent 的工作循环。Agent 写完一段代码,就能知道类型检查过没过、测试挂在哪、是否违反项目规则。
落地方式大概有两种:
- reviewer agent:单独有一个 Agent 跑检查并触发修正。
- companion process:旁边跑一个进程,Agent 随时查询结果。
重点不是多一个工具,而是时序变了。校验从提交之后前移到编码过程中。这个变化对 Agent 很重要,因为它需要即时反馈才能继续收敛。
另一个有意思的点是,自定义检查器变便宜了。以前写一条项目专属规则可能要花几天,现在 Agent 可以根据「我们项目最近总出现这种漂移」快速生成一个检查器。当然,检查器本身仍然要被审。
3. 把 Agent 锚定到参考应用
环位:Assess
怎么让 Agent 知道「我们项目的标准长什么样」?
写文档当然可以,但文档会过期。框架升级了,代码模式变了,README 可能还停在三个月前。Agent 读了过期文档,反而会被带偏。
Thoughtworks 的建议是维护一个活的 reference app:一个能编译、能运行的小应用,里面放着项目的结构、约定和工作流。Agent 写代码时,可以通过 MCP 查询这个参考应用,把当前改动和标准实现对照起来。
大致做法是:
- 维护一个完整可运行的
reference-app仓库。 - 新服务从它派生脚手架。
- Agent 写代码时查询参考应用的当前实现。
- 标准变化时,直接改参考应用。
这比纯文档硬一点。因为代码如果不能编译,马上会暴露;文档过期却不一定有人发现。
4. 反馈飞轮
环位:Assess
前面几个机制做完之后,还有一个问题:它们自己怎么演进?
项目会变,规约会变,Agent 的失败模式也会变。反馈飞轮的做法是把每次 Agent 会话当成一条实验记录:哪里做对了,哪里需要人介入,哪里是指令不清楚,哪里是检查器漏了。
然后人回头看这些记录,把发现补回 shared instructions、反馈传感器或参考应用。
这不是直接写业务代码的技术,更像是改进「写代码的系统」。短期看有点绕,长期看很有用。否则 Agent 工作流会停留在搭好那一天,后面继续老化。
Thoughtworks 还提到更进一步的形态:让 Agent 根据累积反馈自己决定该改进什么。但这个阶段还需要人看着,不然上下文腐烂和噪声反馈会把系统带偏。
5. 把代码异味映射到重构方法
环位:Assess
检查器发现问题之后,Agent 经常不知道怎么修。它会选一个最常见的重构方法,但那未必是项目想要的。
这个技术把「异味」和「修法」明确配对,做成 Agent 可查询的映射。
一层是通用规则,比如 long method 对应 Extract Method,可以参考 Martin Fowler 的《Refactoring》。
另一层是项目规则,比如「query hook 使用字符串 queryKey」对应「改成数组 queryKey,并补 staleTime」。这类规则必须由项目自己沉淀。
这样做之后,工具不只是告诉你「这里有问题」,还会告诉 Agent「这种问题按这种方式修」。这能减少 Agent 自己发挥的空间。
三、具体工具
Spectral
Vol. 34 中未单独评级,作为架构漂移减弱里的确定性分析工具出现。
Spectral 是 OpenAPI / AsyncAPI 规约检查器。你给它一份 API 描述和一组 YAML 规则,它检查规约是否符合约定。
示例:
rules:
financial-amount-decimal-places:
description: "金额字段必须用 multipleOf: 0.01 限制到两位小数"
severity: error
given: "$.components.schemas..[?(@.format == 'currency')]"
then:
field: "multipleOf"
function: pattern
它检查的是 API 规约,不是实现代码。在规约优先的流程里,这很有用:规约是契约,规约对了,下游生成和实现才更可能对。
ArchUnit
Vol. 34 中未单独评级,作为确定性分析工具出现。
ArchUnit 是 Java 生态里的架构测试库。它读取 Java 字节码,把类结构导入测试里,然后用单元测试断言架构规则。
典型用法:
@Test
public void controllers_should_not_directly_access_repositories() {
JavaClasses classes = new ClassFileImporter().importPackages("com.myapp");
ArchRule rule = noClasses()
.that().resideInAPackage("..controller..")
.should().dependOnClassesThat().resideInAPackage("..repository..");
rule.check(classes);
}
它的优点是直接复用现有测试基础设施。违反架构约束时,mvn test 就会失败,不需要额外流程。在 Java 项目里,这基本是成熟做法。
Spring Modulith
Vol. 34 中未单独评级,作为确定性分析工具出现。
Spring Modulith 是 Spring 的模块化单体方案。它用包结构定义模块边界,每个模块暴露明确接口,模块之间不能随便访问内部实现。
常见做法是用 ApplicationModules.of(MyApplication.class).verify() 检查模块边界。它还提供事件机制,让模块间通信不必直接依赖。
它回答的是一个老问题:不上微服务时,单体怎么不烂掉?Spring Modulith 给的答案是,先把单体内部边界管住,必要时再拆。
CodeScene
环位:Assess
CodeScene 做行为代码分析。它结合代码复杂度和 git 历史,找出 hotspot。
它会看两类数据:
- 代码复杂度:圈复杂度、嵌套深度等。
- 变更频率:文件多久改一次、多少人改过。
高复杂度加高变更频率,才是真正值得优先处理的位置。复杂但没人碰的代码可以先放着;简单但经常改的代码也不一定危险。风险在二者重叠的地方。
Vol. 34 特别提到,AI Agent 可以更快地修改代码,所以代码质量本身变得更重要。这个判断我认同。Agent 让改动速度变快,但它不会自动降低复杂度。
cargo-mutants
环位:Trial
这是七个工具里唯一进入 Trial 的。
cargo-mutants 是 Rust 生态的 mutation testing 工具。它会自动改你的源代码,比如把 > 改成 >=、删除一行、把 true 改成 false,然后重新跑测试。
如果测试还能通过,说明这段逻辑就算变错了,测试也没发现。
传统覆盖率只能说明代码被执行过,不能说明它被验证过。变异测试测的是测试套件有没有真的抓住行为。AI 时代这点更重要,因为 Agent 很容易写出覆盖率好看、断言很弱的测试。
WuppieFuzz
环位:Assess
WuppieFuzz 是面向 REST API 的覆盖率引导式 fuzzing 工具,由 TNO 开发,基于 LibAFL。
它读取 OpenAPI 规约,生成大量随机或半随机请求,向 API 发送。覆盖率反馈会引导下一轮请求,尽量探索没走到的代码路径。它主要抓崩溃、5xx,以及不符合规约的响应。
这类工具在 AI 时代的价值更明显了。Agent 写出来的 API 代码,经常在「合法但奇怪」的输入上翻车。fuzzing 很适合批量找这种边界。
Beads
环位:Assess
Beads 是给 AI 编码 Agent 用的任务追踪器。底层基于 Dolt,一个带版本控制能力的 SQL 数据库。
它的定位不是给人看的 Jira,而是给 Agent 用的结构化任务图。它支持 blocker 关系、ready-work 检测,也更适合跨分支、跨会话协作。
这个方向代表了一类新工具:agent-native infrastructure。它默认 AI 是工作流的一部分,而不是外面临时叫来的助手。
四、这些方案放在一起怎么看
把这些技术和工具合起来看,Thoughtworks 的方案大概分三层。
第一层是发现问题:Architecture Drift Reduction,以及 Spectral、ArchUnit、Spring Modulith、CodeScene、cargo-mutants、WuppieFuzz。
第二层是处理问题:Mapping Code Smells to Refactoring Techniques,以及 Feedback Sensors for Coding Agents。
第三层是让机制自己演进:Anchoring to Reference Application 和 Feedback Flywheel。
这三层连起来,才像一个完整系统:先发现问题,再把问题变成可执行动作,最后把每次动作里的经验回收进下一轮工作流。
但有一点不能忽略:这套体系整体还不算成熟。
五个技术思路里,只有「反馈传感器」进入 Trial,其余都在 Assess。七个工具里,也只有 cargo-mutants 进入 Trial。Spectral、ArchUnit、Spring Modulith 本身成熟,但在本卷里只是被引用,没有单独评级。
这个分布说明一件事:目前更稳的方向,还是把传统确定性校验前移到 Agent 工作流里。编译器、类型检查、测试、lint、架构规则,这些仍然是地基。
至于让大模型进入校验循环,或者让 Agent 自己维护反馈飞轮,还在观察阶段。
我的判断是:AI 时代的代码质量治理,不应该从「让 AI 审 AI」开始,而应该先把项目里能确定的东西变成机器可执行规则。大模型可以补语义判断,但不能替代地基。